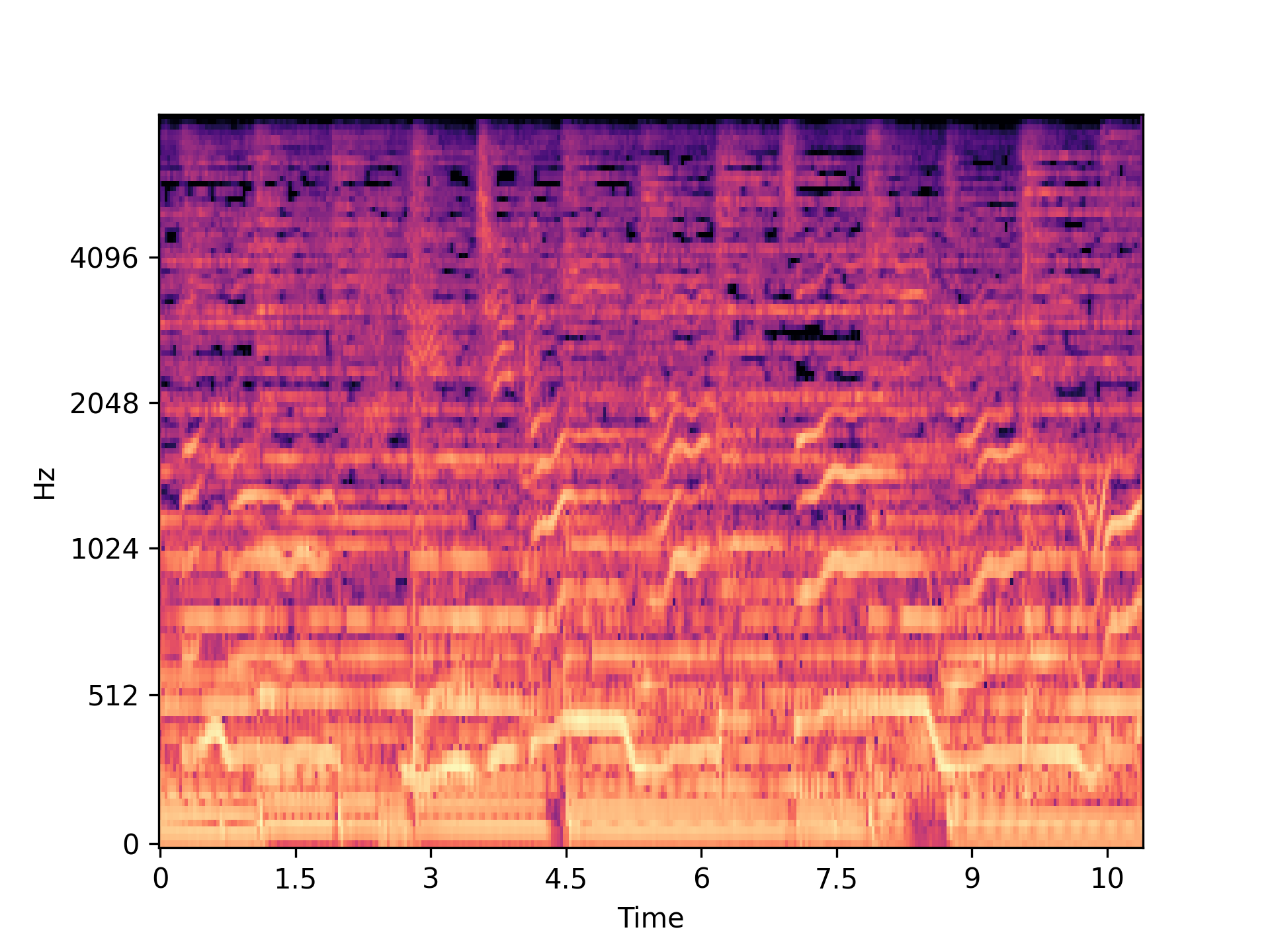
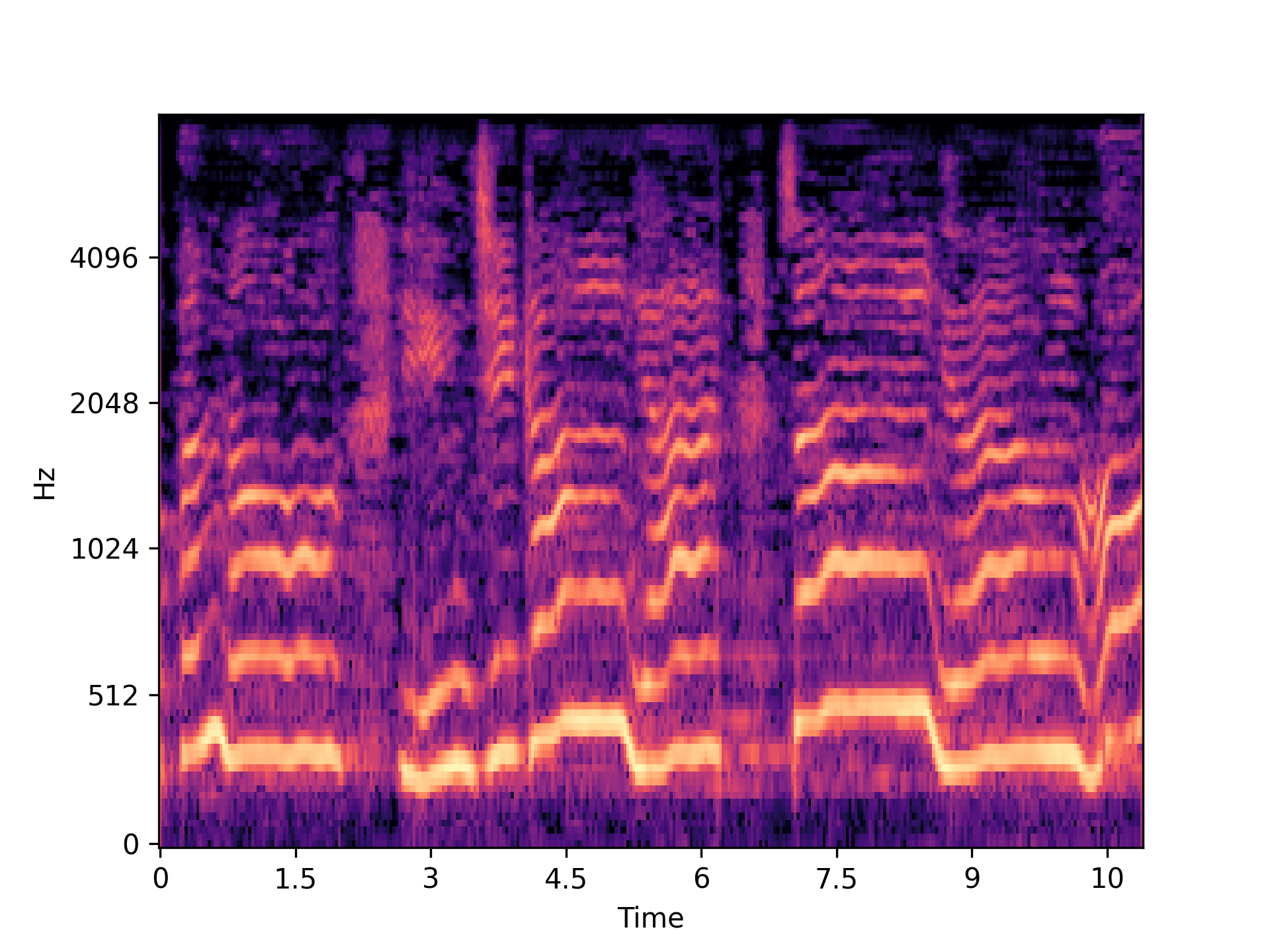
The rise of singing voice synthesis presents critical challenges to artists and industry stakeholders over unauthorized voice usage. Unlike synthesized speech, synthesized singing voices are typically released in songs containing strong background music that may hide synthesis artifacts. Additionally, singing voices present different acoustic and linguistic characteristics from speech utterances. These unique properties make singing voice deepfake detection a relevant but significantly different problem from synthetic speech detection. In this work, we propose the singing voice deepfake detection task. We first present SingFake, the first curated in-the-wild dataset consisting of 28.93 hours of bonafide and 29.40 hours of deepfake song clips in five languages from 40 singers. We provide a train/val/test split where the test sets include various scenarios. We then use SingFake to evaluate four state-of-the-art speech countermeasure systems trained on speech utterances. We find these systems lag significantly behind their performance on speech test data. When trained on SingFake, either using separated vocal tracks or song mixtures, these systems show substantial improvement. However, our evaluations also identify challenges associated with unseen singers, communication codecs, languages, and musical contexts, calling for dedicated research into singing voice deepfake detection.
.svg)
SingFake dataset partition. Each color represents a subset, and each slice denotes an AI singer.
T03 is excluded here since it contains the same song clips as T02 but is repeated 4 times through 4 different codecs.